

What Is Enriched Content?
Enriching content is a sequence of operations that involves adding difference aspects of context around the content by using supervised and unsupervised initiatives through natural language processing and machine learning. Sounds confusing, right? Really, what content enrichment is about is tagging and categorizing content to make it searchable and more usable.
The main challenges in content enrichment are the inherent vagueness and semantics of natural languages. Additionally, the amount of content in the repositories combined with varied content formats makes it extremely difficult for users to navigate and retrieve. In this article, I will discuss content enrichment, with a focus on both different disciplines and Lumina’s unique approach to this increasingly important task.
Limitations of “Off-the-Shelf” Search Engines
First, let’s consider the limitations of “off-the-shelf” search engines. Some specialized search programs come with features like faceted search, which filters based on specific categories. For example, if the user is searching for watches in an online store, the filters can be set for analog vs. digital, merchandising information (such as price), most purchased model, etc. These search features are very useful for e-commerce searches, where the products are catalogued and databased.
On the other-hand, Elasticsearch is a search that enriches and indexes the data. This is general enrichment, rather than enrichment based on the context of the documents. For example, a search for crane will report Grus antigone (a type of bird) and also truck-mounted, hammerhead tower, and stacker (types of industrial cranes). This ambiguity in results shows the need for a custom tool that can operate on non-databased, markup content and enrich the data based on the context of the document(s), perform searches, and report meaningful outcomes. Lumina’s custom enrichment tool takes into consideration the challenges in achieving precision enrichment—and how to overcome them.
Preparing Content for Enrichment
The first step is preparing the content. In order to prepare data for enrichment, several steps must be performed simultaneously. The results are then stored in metadata and applied in different stages. Let’s take a look at what that means.
Parts-of-Speech Tagging

Parts-of-speech tagging, a standard by which every word in the content is assigned to its syntactic function, is performed, chunking each word into one of the 8 grammatical forms (nouns, pronouns, verbs, adjectives etc.).
Gathering Key Terms
Gathering key terms is a critical type of tagging. Each sentence is parsed for possible key terms, and the nodeweight of the key terms are recorded in metadata. More than one algorithm can be used to gather key terms; an appropriate one is chosen and configured depending on the type of content. At times, combined words form a meaningful key term rather than an individual word, and that must be considered as well. For example, applied physics will be more relevant as a single, combined key term than separate instances of the words applied and physics.
Suffix-Stripping Algorithms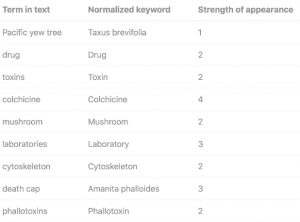
The strength of certain keywords adds another dimension to keyword identification. Natural languages use various inflected forms of words to fit into tense, grammar, etc. For example, the word award might be used in different forms: awarded, awarding, awards, and so on. The strength of the keyword is determined after normalizing the terms.
Word-Sense Disambiguation
Proper nouns often refer to more than one person, place, or organization, and cause ambiguity for AI programs, and subsequent data processing is needed to resolve the ambiguity. For example, the term Edison can refer either to the name of a person, place, or movie. Named entity recognition and disambiguation programs annotate the terms with what they stand for in the context—Edison as a person, Edison as a movie, or Edison as a place—by recognizing the underlying content.
|
Content |
Recognized |
|
Edison and I were at the mall yesterday when the snowstorm hit. |
Edison as person |
|
During rush hour, it takes an extra hour to drive through Edison to get to the airport. |
Edison as a place |
|
If you enjoy crime and mystery, Edison will interest you. |
Edison as a movie/drama/variety show |
Content Classification
To improve the discoverability of content, terms related to the key terms are automatically tagged. A word from natural language can have more than one meaning (homonym) based on the context in which it appears. For example, as we saw earlier, the term crane can refer to either industrial equipment or a bird.
It will be appropriate to show the crane (bird) results for users searching bird-watching but not the crane (industrial equipment) results. A direct enrichment by adding both class labels (bird and industrial equipment) to the term crane will not yield the desired results. Based on the subject matter of the content, an intelligent classification method must be adopted.
Lumina’s Method
Lumina’s classification techniques are built using more than one specialized approach in machine learning and predictive modeling. Classification predictive modeling involves assigning trained datasets, which are appropriate class-labels based on a specific dataset, validated by subject matter experts. Each of these class-labels contribute independently to the probability of classification to find the maximum likelihood of content type in a semi-supervised environment. Based on this model, a multi-label classification with percentage of likelihood is reported.
The content classification algorithm has various other applications, too. It can be used to:
- automatically map a taxonomy domain to a specific segment of content or an assessment question and determine the difficulty level of an assessment.
- verify if the content complies with the required standards in order to generate a gap analysis.
- identify and annotate which parts of the content map to which learning objectives.
- avoid gender-biased content (e.g., use of fireman as opposed to firefighter).
- identify how many male and female characters are referenced in the content (to avoid any gender-bias).
- generate metadata tags for content (date/time of content, characters referenced, genre, etc.).
- flag discriminatory or derogatory content, profane language, etc., based on basic filtering and deep analysis.
Content Enrichment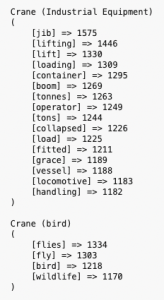
Classifying content reduces vagueness, and—based on the context in which it is referred—identifies it. Enrichment can be applied based on context in which only meaningful enrichment is made. Lumina’s content enrichment modules use natural language toolkits with a superset of key terms and algorithms in order to measure the relationship between two vectors and subsequently tag appropriate key terms based on the classifications made.
An index score helps configure the extent of enrichment needed. The results are maintained in compliance with the Resource Description Framework, a W3C standard for metadata models for packaging this information and storing in the CMS.
Summarizing Content
An emerging requirement in educational publishing is the need to discern the content without going through several pages of text. Lumina’s auto-summarization tools work on pre-existing content and summarize it using two approaches:
- Abstractive summarization: Abstractive summarization is the process of replicating manual summarization. The processes is similar to how a person reads content and re-writes it in a different language. The semantics and words used in this may differ from the original content. This requires pre-trained data sets, and the AI programs are executed over the new data.
- Extractive summarization: Based on keywords extracted from the source document, multiple documents, or a pre-defined set of key terms, these programs grab a concise and fluent summary of sentences that has the highest relevance to the key terms (topic and key term representation). Both topic and key term representation are then parsed against every chunk of the content to assign a sentence scoring, with the highest-scoring sentences added to the summary. The length of the summary can be adjusted based on user requirements. Other than a dataset of key terms, no other trained dataset will be needed.
Searching Non-Text Content
Searching for specific information within images and videos has always been a challenge. The addition of accessibility requirements for published media (such as alt text or video transcriptions) has helped data gathering to a certain extent, but other challenges remain, such as how to search repositories for similar images.
Lumina’s image recognition and similarity indexing solutions help build a text representation of images and stores them as metadata, which is made searchable. Using computer vision techniques, a sparse set of keywords is created and tied together to form meaningful descriptions of the images.
It Works
More and more companies are investing heavily in content and search-related technologies in order to provide meaning to their content. For example, when a top publishing company of both higher education and journal content wanted to connect their higher education readers with relevant journal articles to enhance their learning, they turned to Lumina, where we developed a blueprint for content enrichment of the publisher’s textbooks and journals. Through this blueprint, we identified and mapped related topics, further readings, linked content, and media resources, leading to highly enriched content that enabled lifelong learning.
Interested in learning more about how Lumina can help your team develop a unique solution to enrich your content, making it more searchable, discoverable, and usable? Email Lumina to request a demo, or visit our website to learn more about Lumina Datamatics.

0 Comments